In this article we're going to create our own AI chat, capable of indexing markdown and PDF documents and answering questions about said documents completely for free and hosted locally using Python3, LlamaIndex, Qdrant and Ollama.
Core Concepts
Retrieval-Augmented Generation (RAG):
RAG is a way of optimizing a large language model using your own knowledge base. It consists of storing your documents in a database, matching them against the user's query, and providing the document as context to the LLM to generate an informed answer. It is often used in search engines and chat applications.
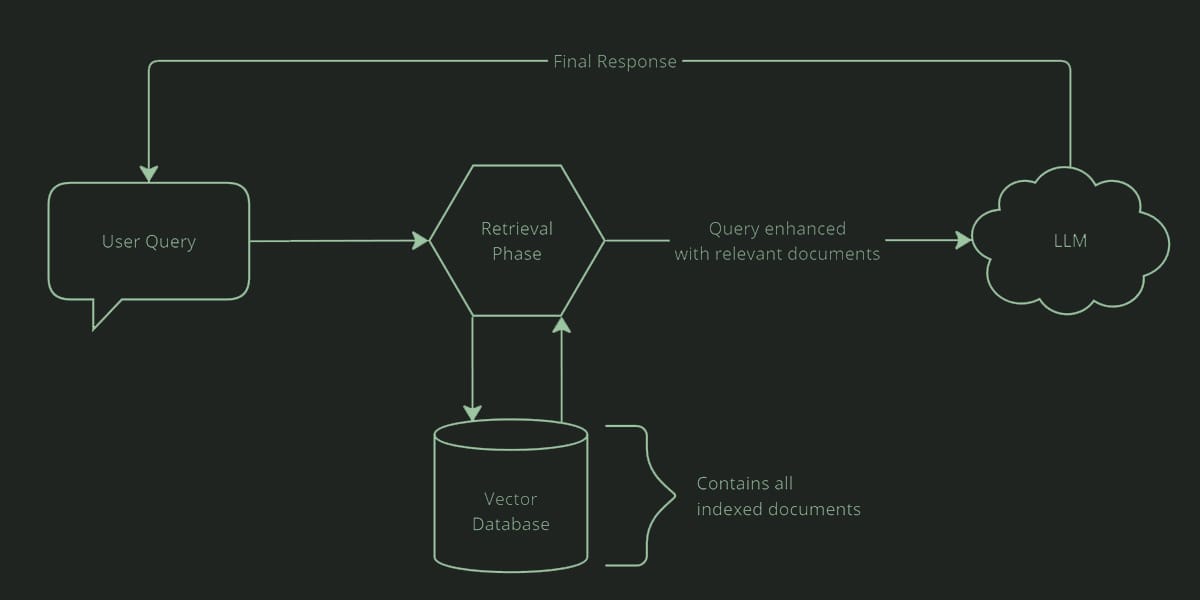
Vectors:
Vectors are simply an array of numbers, but there are AI models that are used to transform text into multidimensional vectors, making it easy to group chunks of text by meaning, topic, semantic and gramatical similarities. These models are are called embedding models, and we will be using a model called bge-small-en-v1.5 which is available at HuggingFace

Vector Databases:
Vector databases are just like other DBMS like PostgreSQL or MongoDB, but they are optimized for storing and querying vectors, making them very useful for our RAG. We will use the Qdrant Vector Database because it is open-source and very easy to set-up.
Step 1: Project Setup
For this tutorial you will need to have python and docker installed in your system.
First, create a folder for your project, and create a python virtual environment to install the dependencies.
python -m venv venvThis will create the venv/ directory, you can activate the virtual environment using
source venv/bin/activateThen, we need to install the dependencies for this project using PIP
pip install qdrant_client llama-index ollama torch transformersNext, we need to create a docker-compose.yml file to setup our Qdrant container.
# docker-compose.yml
services:
qdrant:
image: qdrant/qdrant:latest
restart: always
container_name: polyrag-qdrant
ports:
- 6333:6333
- 6334:6334
expose:
- 6333
- 6334
- 6335
configs:
- source: qdrant_config
target: /qdrant/config/production.yaml
volumes:
- ./qdrant_data:/qdrant/storage
configs:
qdrant_config:
content: |
log_level: INFOdocker-compose.yml
Running docker compose up -d should pull, build and start your qdrant instance

That should allow you to access Qdrant's WEB UI on port 6333 to manage your collections
http://localhost:6333/dashboard
Then, you can click on the console tab in the left to run HTTP requests directly in your browser to create, fetch and manage collections easily.
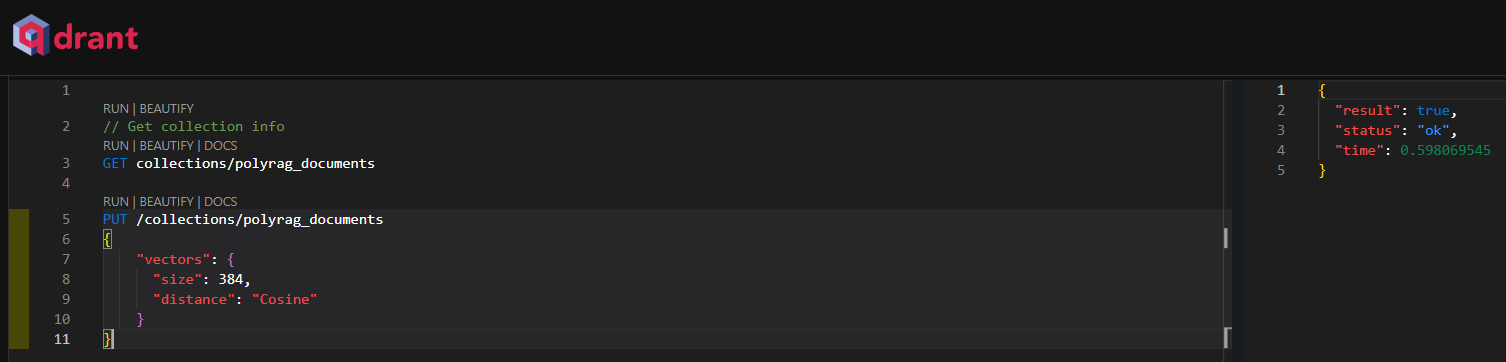
Let's create a collection to store our indexed documents, I'm calling my collection "polyrag_documents".
The "size" parameter depends on the Embedding Model that you're going to use, the model I'm using is bge-small-en-v1.5 which produces a vector with the dimension 384, that's where this number comes from.
PUT /collections/polyrag_documents
{
"vectors": {
"size": 384,
"distance": "Cosine"
}
}
Now we can start working on our indexer. I want it to index all the documents inside the data/ folder that I'll create. For now I'll just create a demo document called document1.md with a review of the movie Fight Club
# Fight Club Review
Pitt dominates the screen every second he's on it, and it simultaneously represents his weirdest, funniest and most charismatic role of his career./data/document1.md
I'll create a file called indexer.py to run all the embedding and indexing into our Qdrant server.
The first step is importing Ollama, the Qdrant client, and some tools from LlamaIndex to create a connection to our database.
LlamaIndex is a library that will greatly help us speed up the process of setting up our RAG, it comes with a variety of tools to help us ingest and query our documents.
# Import modules
from llama_index.llms.ollama import Ollama
import qdrant_client
from llama_index.core import SimpleDirectoryReader, StorageContext, Settings
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.extractors import TitleExtractor
from llama_index.core.ingestion import IngestionPipeline
# Initialize Ollama and set LlamaIndex Settings
Settings.llm = Ollama(model="mistral")
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
# Create a Qdrant client and connect to our qdrant server and collection
client = qdrant_client.QdrantClient(url="http://localhost:6333")
vector_store = QdrantVectorStore(client=client, collection_name="polyrag_documents")
storage_context = StorageContext.from_defaults(vector_store=vector_store)indexer.py
Now let's create an ingestion pipeline to process our documents and add them to Qdrant.
You can tweak the settings for your use-case, I'm using chunk_size=1024 and chunk_overlap=64.
# Create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=1024, chunk_overlap=64),
TitleExtractor(),
HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5"),
],
vector_store=vector_store
)
# Load markdown and pdf documents
reader = SimpleDirectoryReader(input_dir="./data", required_exts=[".pdf", ".md"])
documents = reader.load_data()
# Run our ingestion pipeline
pipeline.run(documents=documents)
print("Document indexing completed.")indexer.py
We can now run python indexer.py to pull the embedding model from HuggingFace and index our files in the database.

Alright, so now we need a way to interact with the data we've indexed, so let's create another file called chat.py to create a conversation loop.
The first lines of this file are very similar to indexer.py as we will also need to connect to qdrant in the same way, however we don't need to import the ingestion pipeline as we will only be reading from the database in this file.
# Import modules
from llama_index.llms.ollama import Ollama
import qdrant_client
from llama_index.core import VectorStoreIndex, StorageContext, Settings
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# Initialize Ollama and ServiceContext
Settings.llm = Ollama(model="mistral")
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
# Create Qdrant client and store
client = qdrant_client.QdrantClient(url="http://localhost:6333")
vector_store = QdrantVectorStore(client=client, collection_name="polyrag_documents")
storage_context = StorageContext.from_defaults(vector_store=vector_store)chat.py
Then, we can create a LlamaIndex query engine to interact with our database, and define a loop that asks for the user's input and sends it as a query to our index, and repeats until the user types in "bye".
# Create VectorStoreIndex and query engine
index = VectorStoreIndex.from_vector_store(
vector_store=vector_store
)
query_engine = index.as_query_engine()
print('PolyRAG started, ask any questions about your documents or type \'bye\' to leave')
# chat loop to perform a query and print the response
running = True
while running:
query = input('$ you -> ')
if query == 'quit' or query == 'exit' or query == 'bye' or query == 'close':
running = False
else:
response = query_engine.query(query)
print('$ polyrag -> ', response)chat.py
So now we can run python chat.py to interact with our LLM enhanced with our knowledge base (everything in the /data/ folder).
python chat.pyPolyRAG started, ask any questions about your documents or type 'bye' to leave
$ you -> what does the author think about fight club
$ polyrag ->
The author seems to hold a positive opinion towards Fight Club, as indicated by
their statement that Brad Pitt dominates the screen every second he's on it and
that this role represents Pitt's weirdest, funniest, and most charismatic
performance of his career. This suggests that they found the movie engaging and
enjoyed Pitt's performance in it.
$ you -> Note that everytime you need to add a new file to the knowledge base, you must copy it to the /data/ folder and run python indexer.py again.
That's it! Your simple RAG application is ready. Feel free to extend it's funcionality however you see fit.
This article covers the basis of how I created PolyRAG, a python server based on FastAPI to index and query files just like we did here. You can check the source code for PolyRAG here.